法律のデータ構造と検索

デジタル庁は、法令標準 XML スキーマに準拠した、現行の法令データをe-Gov法令検索というサイト上で公開しています[1]。今回、この法令XMLをパースするPythonライブラリ ja-law-parser をつくり、法令データの全文検索をしてみました。
この記事では、日本の法令とそのデータ構造、法令XMLパーサについて解説し、最後に、それらを使った法令データの全文検索システムを実装する方法をご紹介します。法令検索の実装についても、GitHubリポジトリで公開しています。
この記事は、情報検索・検索技術 Advent Calendar 2023の16日目の記事です。
法律と法令
法律とは
法律とは、主に国家によって定められる、強制力をもった規範です[2]。日本の法律は、国会の議決を経て制定されます。
社会生活を営むにあたって法やルールを遵守することが大事なのは言うまでもありませんが、知らず知らずのうちに法律に違反したことで制裁が課されたり社会的な信用を失うこともあるため、法律を正しく知ることは重要です。
法律の制定と公布
日本において法律案は、国会議員もしくは内閣から提出され、定められたワークフローに則り審査が行われます。それが可決されると、法律として制定され、官報(紙媒体)で公表されます。これを法律の公布といいます。公布された法律は、定められた施行日から効力を発揮します(公布日と施行日が同日になることもあります)。
たとえば内閣が提出した法律案(閣法)は、以下のプロセスで審議・成立・公布されます[3]。
- 法律案の原案作成
- 内閣法制局における審査
- 国会提出のための閣議決定
- 国会に置ける審議
- 法律の成立
- 法律の公布
公布された法律は、官報(紙媒体)だけでなく、e-Gov法令検索(旧法令データ提供システム)をはじめとした、以下のようなオンラインサービスやデータベースでも公開されます[4]。
- e-Gov法令検索(デジタル庁)
- 日本法令索引(国立国会図書館)
- 制定法律(衆議院)
- インターネット版官報(国立印刷局)
- 現行法令電子版 Super法令Web(ぎょうせい)
- D1-Law.com 現行法規(第一法規出版)
- LexisNexis JP(レクシスネクシス・ジャパン)
- Westlaw Japan(ウエストロー・ジャパン)
法律と法令の違い
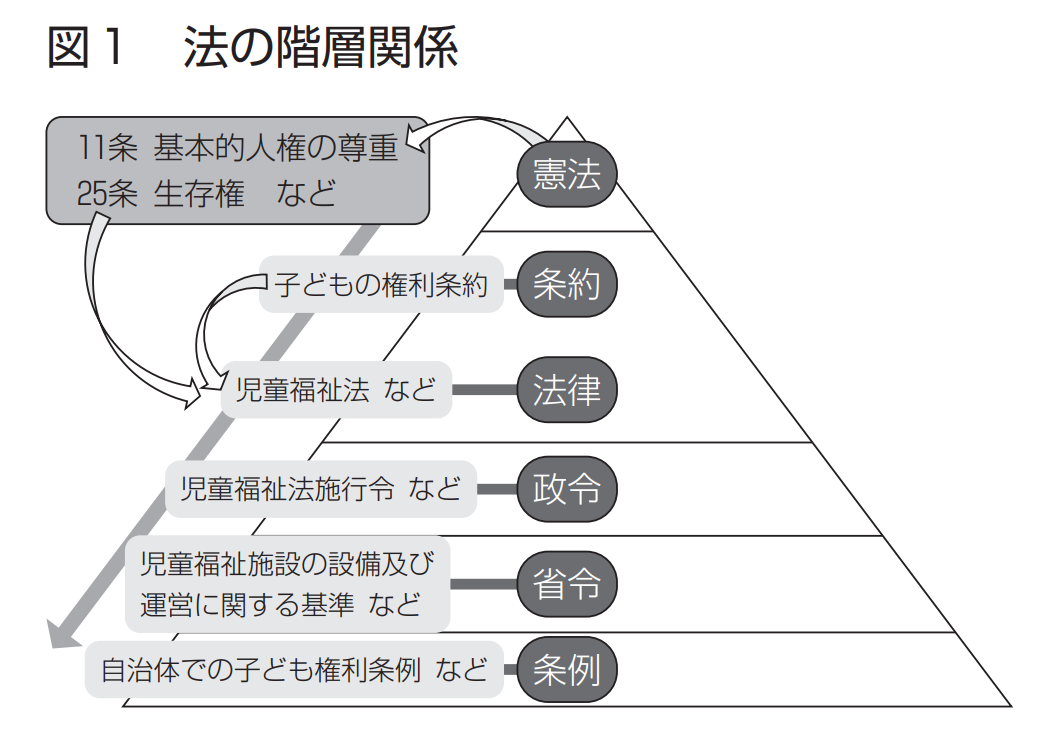
法令というのは、法律に加えて、憲法や政令などを含んだ法規範のことを指します。一般には以下のものを含むようです[5][6]。
- 憲法
- 条約
- 法律
- 政令
- 命令
- 政令
- 府令・省令
法令は、より上位の法令が下位の法令より優先される、という階層構造になっています。いいかえると、基本的に上位の法令が優先し、それに違反する下位の法令は効力をもちません。たとえば、憲法は最も強い規範であり、憲法に違反するような法令は無効となります[7]。
この記事では扱いませんが、日本における規範としては他にも、行政機関等が発する訓令・通達・通知・告示や、地方公共団体が制定する条例・規則などがあります。
法律の改正
日本における法律の改正には、法令の全文を改める全部改正と、条文の一部を改める一部改正があります。
全部改正の場合は、新たな法令として制定されます(法令番号も変わります)。もとの法令と題名は同じままになることが多い[8]ため、区別できるよう、題名につづく制定文において「〜法の全部を改正する」という記述がなされます。たとえば、全部改正された法令の一つとして、著作権法(昭和四十五年法律第四十八号)があり、制定文には「著作権法(明治三十二年法律第三十九号)の全部を改正する。」と書かれています。
一部改正の際、日本では溶け込み方式と呼ばれる方法をとっており、条文の変更内容を既存の条文に適用し、上書きしてしまいます(溶かし込みといいます)。つまり、改正の内容を追跡しなくても、その時点で有効な法令の内容が一目でわかるようになっています。しかし、法令データでは改正前の条文に溶かし込まれた状態で公開されるため、変更内容がわからなくなっています。変更内容は、官報や法令全書においては、一部改正法として公布されるので、変更点を知りたい場合は、そちらもあわせて確認する必要があります[5:1]。
また、法令を改正するにあたって、全部改正とは異なり、既存の法律を廃止し、新たにそれに代わる法令を制定する廃止制定があります[9]。全部改正と似ていますが、こちらには制定文に「〜法の全部を改正する」という記述はされません。その代わり、附則にて、「〜法は廃止する」という記述がなされます。国籍法(昭和二十五年法律第百四十七号)は題名は同じですが、国籍法(明治三十二年法律第六十六号)が廃止制定されたもので、附則2項に「国籍法(明治三十二年法律第六十六号)は、廃止する。」と書かれています。
法令のデータ構造
e-Govの法令データ
e-Gov法令検索が公開している法令データ(以下、単に法令データとします)は、2023年12月16日現在、以下の9,111件です[10]。
| 法令種別 | 登録数 |
|---|---|
| 憲法 | 1 |
| 法律 | 2,122 |
| 政令 | 2,302 |
| 勅令 | 71 |
| 府省令 | 4,181 |
| 規則 | 434 |
この法令データは、以下のURLから、すべてのXMLが含まれたzipファイル( all_xml.zip )をダウンロードできます。
この法令データは、さまざまなアプリケーションの開発を想定されており、二次利用が可能です。
Q7:e-Gov法令検索で提供しているデータの二次利用をしたいのですが?
A:提供している法令データについては、特に利用制限を設けておりません。
ただし、デジタル庁及び各府省は、本システムの法令データの利用に伴って発生した不利益や問題について、何ら責任を負いませんので、ご承知ください。
法令標準XMLスキーマ
法令データのファイルの内容は、法令標準XMLスキーマ(PDF, xsd)に準拠した形式になっています[11]。
たとえば法令XMLにおいて、もっとも「外側」の要素である、法令( Law )は以下のように定義されています。
<xs:element name="Law">
<xs:complexType>
<xs:sequence>
<xs:element ref="LawNum"/>
<xs:element ref="LawBody"/>
</xs:sequence>
<xs:attribute name="Era" use="required">...</xs:attribute>
<xs:attribute name="Year" use="required" type="xs:positiveInteger"/>
<xs:attribute name="Num" use="required" type="xs:positiveInteger"/>
<xs:attribute name="PromulgateMonth" type="xs:positiveInteger"/>
<xs:attribute name="PromulgateDay" type="xs:positiveInteger"/>
<xs:attribute name="LawType" use="required">...</xs:attribute>
<xs:attribute name="Lang" use="required">...</xs:attribute>
</xs:complexType>
</xs:element>
法令データは、大きくは以下のような構造をもちます(カッコ書きの要素はオプショナル)。
- 法令
Law- 法令番号
LawNum - 法令本体
LawBody- 題名
LawTitle - (制定文
EnactStatement) - (目次
TOC)
- 題名
- (前文
Preamble) - 本則
MainProvision - (附則
SupplProvision) - (別表
AppdxTable、別記AppdxNote、付録Appdx等)
- 法令番号
法令標準XMLスキーマを見やすい形で公開しているサイトがありますので、スキーマについて詳しく知りたい方はそちらを参照するとよいでしょう。
法令番号と法令ID
法令は公布の際に、一意に識別できる法令番号が付与されます。たとえば、現在の会社法の法令番号は「平成十七年法律第八十六号」となっています。
e-Govが提供する法令データでは、各法令に一意な法令IDが付与されます(改正法にも法令IDが付与されます)。たとえば法律の法令IDは、以下のコード体系で決定されます[12]。
| 桁数 | 意味 |
|---|---|
| 1 | 年号 |
| 2-3 | 年 |
| 4-5 | 種別(法律の場合 AC) |
| 6-12 | 閣法と議員立法の区別 |
| 13-15 | 法令の号番号 |
法令が改正された場合、前述のとおり、もとの法令に改正法を溶かし込んだ(マージされた)ものが公開されています。
ただし、法令データには、施行日が未来のもの、つまり未施行の法令が含まれるので注意が必要です。たとえば会社法(平成十七年法律第八十六号)の場合、法令データには未施行のものを含め、以下のファイルが含まれています。
417AC0000000086_20230614_505AC0000000053.xml(2023年6月14日施行 ← 現在有効)417AC0000000086_20250616_504AC0000000068.xml(未施行)417AC0000000086_20251213_505AC0000000053.xml(未施行)417AC0000000086_20260524_504AC0000000048.xml(未施行)417AC0000000086_20280613_505AC0000000053.xml(未施行)
このように、法令データは、法令の改正に対応するため、一意に識別できる形でファイル名がつけられています。
e-Gov法令検索では、いつ時点のデータであるかを明示するために「法令ID_改正法の施行日_改正法の法令ID」をURLとしています。
「129AC0000000089_20200401_501AC0000000034」
つまり、現在有効な法令を探すには、ファイル名に含まれる「改正法の施行日」が過去のものを対象にする必要があります。
題名
法令番号だけではどんな法令なのか認識しづらいこともあり、新たに制定される法令には、題名( LawTitle )がつけられ、法令が判別しやすくなっています。
ただし、昭和22年ごろまでに制定された法令のなかには題名のないものがありました。しかし、法令番号だけでは意味を類推できず、不便です。そのため、題名のない法令については、公布文から件名をとって便宜的な法令名として扱うようです。
たとえば、決闘罪について規定された明治二十二年法律第三十四号には題名がありません。この法令は「決闘罪ニ関スル件」と呼ばれており、法令データでも「明治二十二年法律第三十四号(決闘罪ニ関スル件)」という題名がつけられています。
本則と附則
法令の構造は、大きくは法令の実質的な内容が書かれている本則( MainProvision )と、条文の施行期日などの付帯的な情報が書かれた附則( SupplProvisoin )からなります(「法令標準XMLスキーマ」の項目を参照)。
附則では、その法令によって影響を受ける関連法令についても言及されることがあります。また、本則の特例など例外事項について書かれることもあり[13]、附則も本則とあわせて確認する必要があります。
条・項・号
法令の内容のもっとも基本的な単位は条( Article )であり、法令は条(条文)の集まりからなる、と考えることができます[7:1][14]。
では、条の構造を詳しく見ていきましょう。以下は、労働基準法(昭和二十二年法律第四十九号)の第24条を抜粋したものです。この条には、以下のように2つの項があります。
(賃金の支払)
第二十四条 賃金は、通貨で、直接労働者に、その全額を支払わなければならない。ただし、法令若しくは労働協約に別段の定めがある場合又は厚生労働省令で定める賃金について確実な支払の方法で厚生労働省令で定めるものによる場合においては、通貨以外のもので支払い、また、法令に別段の定めがある場合又は当該事業場の労働者の過半数で組織する労働組合があるときはその労働組合、労働者の過半数で組織する労働組合がないときは労働者の過半数を代表する者との書面による協定がある場合においては、賃金の一部を控除して支払うことができる。
② 賃金は、毎月一回以上、一定の期日を定めて支払わなければならない。ただし、臨時に支払われる賃金、賞与その他これに準ずるもので厚生労働省令で定める賃金(第八十九条において「臨時の賃金等」という。)については、この限りでない。
法令データにおいて条( Article )は、条名( ArticleTitle )や条見出し( ArticleCaption 、省略可)、そして一般には複数の項 ( Paragraph ) から構成されます(項が1つだけの条も多い)。項は、実際の内容が書かれる項文( ParagraphSentence )をもちます。項文は段( Sentence )という文字列型の文のリストとして定義されます。先ほどの第24条は、法令データでは以下のようなXMLになっています。
<Article Num="24">
<ArticleCaption>(賃金の支払)</ArticleCaption>
<ArticleTitle>第二十四条</ArticleTitle>
<Paragraph Num="1">
<ParagraphNum/>
<ParagraphSentence>
<Sentence Function="main" Num="1" WritingMode="vertical">賃金は、通貨で、直接労働者に、その全額を支払わなければならない。</Sentence>
<Sentence Function="proviso" Num="2" WritingMode="vertical">ただし、法令若しくは労働協約に別段の定めがある場合又は厚生労働省令で定める賃金について確実な支払の方法で厚生労働省令で定めるものによる場合においては、通貨以外のもので支払い、また、法令に別段の定めがある場合又は当該事業場の労働者の過半数で組織する労働組合があるときはその労働組合、労働者の過半数で組織する労働組合がないときは労働者の過半数を代表する者との書面による協定がある場合においては、賃金の一部を控除して支払うことができる。</Sentence>
</ParagraphSentence>
</Paragraph>
<Paragraph Num="2" OldNum="true" OldStyle="false">
<ParagraphNum/>
<ParagraphSentence>
<Sentence Function="main" Num="1" WritingMode="vertical">賃金は、毎月一回以上、一定の期日を定めて支払わなければならない。</Sentence>
<Sentence Function="proviso" Num="2" WritingMode="vertical">ただし、臨時に支払われる賃金、賞与その他これに準ずるもので厚生労働省令で定める賃金(第八十九条において「臨時の賃金等」という。)については、この限りでない。</Sentence>
</ParagraphSentence>
</Paragraph>
</Article>
基本的に項文( ParagraphSentence )に含まれる段( Sentence )は1つの本文(属性が Function="main" のもの)のみですが、この第24条のように、ただし書(属性が Function="proviso" )の段( Sentence )をもつことがあります[15]。
項の内容をさらに細分化して記述する必要がある場合には号( Item )が用いられます。著作権法第10条第3項には、3つの号が含まれています。
3 第一項第九号に掲げる著作物に対するこの法律による保護は、その著作物を作成するために用いるプログラム言語、規約及び解法に及ばない。この場合において、これらの用語の意義は、次の各号に定めるところによる。
一 プログラム言語 プログラムを表現する手段としての文字その他の記号及びその体系をいう。
二 規約 特定のプログラムにおける前号のプログラム言語の用法についての特別の約束をいう。
三 解法 プログラムにおける電子計算機に対する指令の組合せの方法をいう。
法令データでは、以下のようになっています(著作権法第10条第3項より第1号までを抜粋)。
<Paragraph Num="3">
<ParagraphNum>3</ParagraphNum>
<ParagraphSentence>
<Sentence Num="1" WritingMode="vertical">第一項第九号に掲げる著作物に対するこの法律による保護は、その著作物を作成するために用いるプログラム言語、規約及び解法に及ばない。</Sentence>
<Sentence Num="2" WritingMode="vertical">この場合において、これらの用語の意義は、次の各号に定めるところによる。</Sentence>
</ParagraphSentence>
<Item Num="1">
<ItemTitle>一</ItemTitle>
<ItemSentence>
<Column Num="1">
<Sentence Num="1" WritingMode="vertical">プログラム言語</Sentence>
</Column>
<Column Num="2">
<Sentence Num="1" WritingMode="vertical">プログラムを表現する手段としての文字その他の記号及びその体系をいう。</Sentence>
</Column>
</ItemSentence>
</Item>
<Item Num="2">
(以下略)
編・章・節・款・目
条文数の多い法令については、編( Part )、章( Chapter )、節( Section )、款( Subsection )、目( Division )という区分を用いて条をまとめます(ただし、必ずしも全ての階層が存在するわけではありません)。
よって一般には、法令の内容(本則)は、以下のような階層構造となります。
- 本則
MainProvision- 編
Part- 章
Chapter- 節
Section- 款
Subsection- 目
Division
- 目
- 款
- 節
- 章
- 編
なお、条名(条番号)は区分をまたいでも通し番号が振られます。つまり、章をまたいだとしても、ふたたび第一条から始めるといったことはしません。
法令XMLパーサ: ja-law-parser
さて、XMLファイルを解析し、なんらかのデータ処理をするときには、適当なXMLライブラリ(Pythonの場合は lxml など)を使ってパースし、XPathで特定の要素を取り出すことになると思います。
ですが、法令データは前述の通り、オプショナルな要素を含む複雑な構造をもっており、場合によっては困難が伴います。目的とする要素を取り出したり、データに応じて柔軟にデータ処理をするには、複雑なXPathを組んだり、深くネストしたコードを書く必要があるかもしれません。また、法令標準XMLスキーマの仕様について適切に理解していないと、目的の要素が抽出できていなかった、といったこともありえます。
そこで、上記の法令標準XMLスキーマに準拠する法令XMLファイルをパースし、Pythonのオブジェクト(pydanticのモデル)に変換するライブラリ ja-law-parser をつくりました。このパーサライブラリは GitHub と PyPI で公開しています。
このライブラリを使って法令データを解析することで、たとえば以下のような利点があります。
- 明示的にXMLを扱わずにすみ、Python APIだけで汎用的なデータ処理ができる
- XMLやXPathの学習コストを払わずにすむ
- 必要な構造のみを簡単に抽出できる
- Pydanticのモデルに変換されるので、pydanticのAPIを利用して、モデルをJSONなどの他のデータ構造に変換できる
ja-law-parser のインストール
pip を使う場合、以下のコマンドでインストールできます。
pip install ja-law-parser
poetry の場合は以下でインストールできます。
poetry add ja-law-parser
ja-law-parser の使いかた
LawParser を import し、 parse 関数にXMLのファイルパスを与える、もしくは parse_from 関数にXMLの内容(文字列もしくはバイナリ)を与えることで、法令( Law )型のオブジェクトが返ってきます。このオブジェクトには与えた法令の情報がすべて含まれているので、自由に属性(attributes)にアクセスしたり、テキストを取り出したりすることができます。
from ja_law_parser.model import Article, Chapter, Law, Paragraph
from ja_law_parser.parser import LawParser
parser = LawParser()
law: Law = parser.parse(path="321CONSTITUTION_19470503_000000000000000.xml")
print(law.law_body.law_title.text)
# => 日本国憲法
chapter3: Chapter = law.law_body.main_provision.chapters[2]
print(chapter3.chapter_title.text)
# => 三章 国民の権利及び義務
article11: Article = chapter3.articles[1]
print(article11.article_title.text)
# => 第十一条
paragraph11: Paragraph = article11.paragraphs[0]
print(paragraph11.paragraph_sentence.sentences[0].text)
# => 国民は、すべての基本的人権の享有を妨げられない。
print(paragraph11.paragraph_sentence.sentences[1].text)
# => この憲法が国民に保障する基本的人権は、侵すことのできない永久の権利として、現在及び将来の国民に与へられる。
法令の検索
前置きが長くなりましたが、法令データをElasticsearchにインデックスし、検索してみましょう[16]。
Elasticsearchのマッピング
今回は簡単に、法令番号( law_num )、題名( law_title )、制定文( enact_statement )、本則のみをインデックスしてみます。Elasticsearchのマッピングはたとえば以下のようになります。
{
"mappings": {
"properties": {
"law_num": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"law_title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"enact_statement": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"main_provision": {
"type": "text"
}
}
}
}
法令データのインデクシング
いよいよ法令XMLパーサで法令データをパースし、Elasticsearchにデータを登録してみましょう。以下のような index_law 関数を書いてみました(実際のコードはGitHubリポジトリにあります)。
from typing import Generator, Protocol
from elasticsearch import Elasticsearch
from ja_law_parser.model import Law
from ja_law_parser.parser import LawParser
def index_law() -> None:
parser = LawParser()
client = Elasticsearch(hosts="http://localhost:9200/")
# 指定したディレクトリに含まれるXMLファイルをイテレート
for file in Path("../data").glob("**/*.xml"):
# ファイル名から法令を識別するIDを抽出(法令ID_改正法の施行日_改正法の法令ID)
file_name = file.stem
# 施行日が未来の法令はインデックスしない
enforce_date = date.fromisoformat(file_name.split(sep="_")[1])
today = date.today()
if today < enforce_date:
continue
# XMLをパースしてpydanticのモデルに変換
law: Law = parser.parse(path=file)
# Elasticsearchにインデックス
client.index(
index="ja_law",
id=file.stem,
document={
"law_num": law.law_num,
"law_title": text_or_none(law.law_body.law_title),
"enactg_statement": text_or_none(law.law_body.enact_statement),
"main_provision": texts_or_none(law.law_body.main_provision),
},
)
class Text(Protocol):
@property
def text(self) -> str:
...
class Texts(Protocol):
def texts(self) -> Generator[str, None, None]:
...
def text_or_none(obj: Text | None) -> str | None:
if obj is None:
return None
return obj.text
def texts_or_none(obj: Texts | None) -> str | None:
if obj is None:
return None
return " ".join(obj.texts())
今回は本則以下のテキストをまるまる検索対象としてインデックスしましたが、特定の要素はスキップするなどの工夫もできそうです。
法令データの検索
検索側のコードは以下のように書けます。今回はシンプルに multi-match query で複数のフィールド(法令番号、題名、本則)を単にフレーズ検索しています。このあたりも色々工夫の余地がありそうです。
from elastic_transport import ObjectApiResponse
from elasticsearch import Elasticsearch
def search_law(keyword: str, size: int) -> ObjectApiResponse[Any]:
client = Elasticsearch(hosts="http://localhost:9200/")
return client.search(
index="ja_law",
query={
"multi_match": {
"query": keyword,
"type": "phrase",
"fields": ["law_num", "law_title", "main_provision"],
}
},
size=size,
fields=["law_num.keyword", "law_title.keyword"],
highlight={
"fields": {"*": {"pre_tags": [" **"], "post_tags": ["** "]}},
"number_of_fragments": 1,
},
)
検索UI
今回はUIとして streamlit を使いました。フォームにクエリを入力してEnterキーを押すと検索結果が表示される、というだけのシンプルなUIです。
import streamlit as st
from japanese_law_search.search import search_law
st.title("Japanese Law Search")
# クエリの入力フォーム
query = st.text_input("Query", value="")
if query:
# 検索を実行して top-20 を取得
res = search_law(index_name="ja_law", keyword=query, size=20)
st.write(f"{res.total_hits} hits")
for doc in res.docs:
c = st.container(border=True)
# 題名と法令番号、e-Govへのリンクを表示
c.markdown(
f"[{doc.law_title}({doc.law_num})](https://elaws.e-gov.go.jp/document?lawid={doc.id})"
)
# ヒットしたフィールドのハイライトを表示
c.caption(
"".join(["".join(highlites[0]) for highlites in doc.highlight.values()])
)
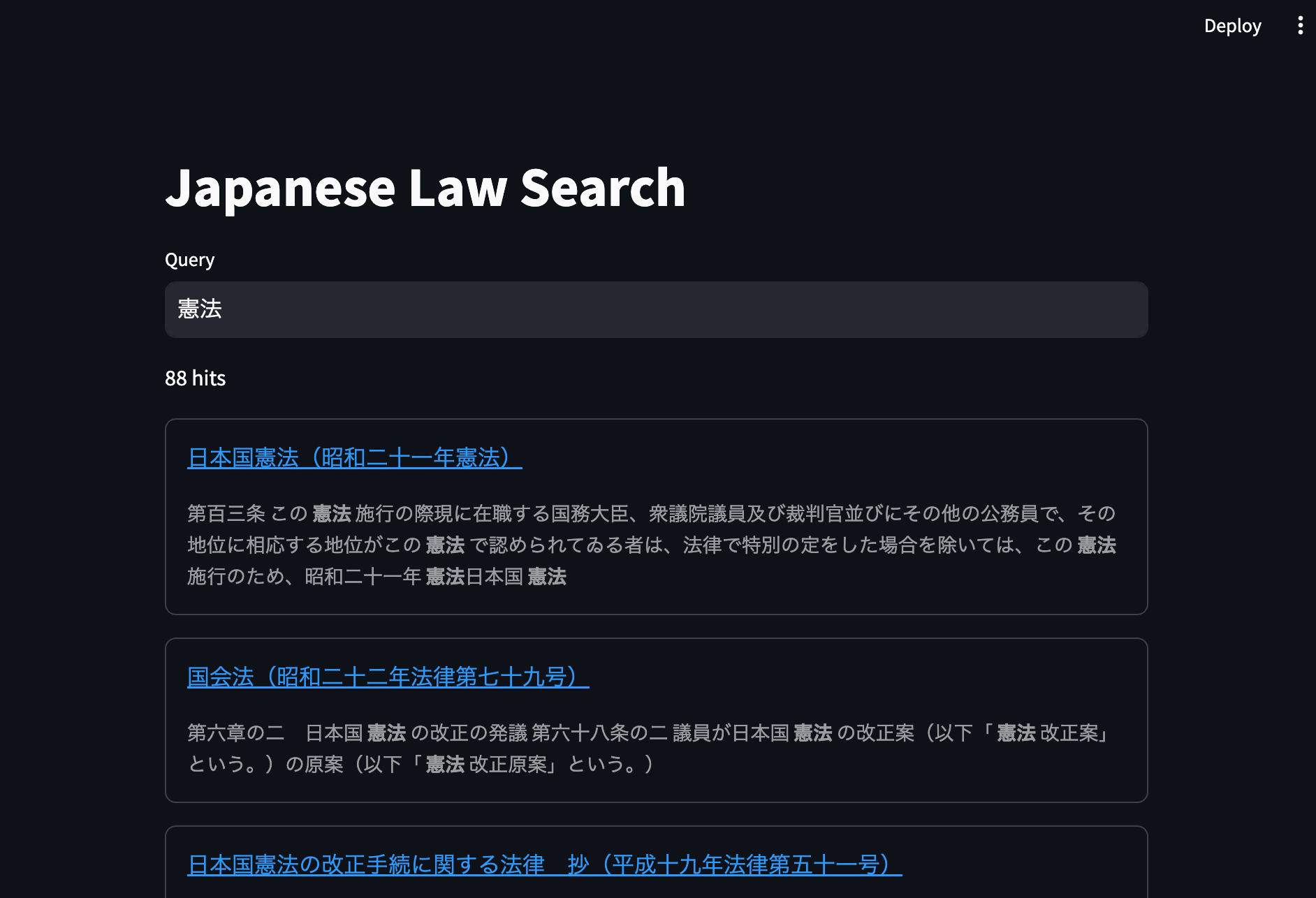
要素が少ないとはいえ、これだけのコードで簡単に検索画面のWeb UIが作成できてしまいます。実際に検索してみると、こんな感じで検索結果が表示されます。
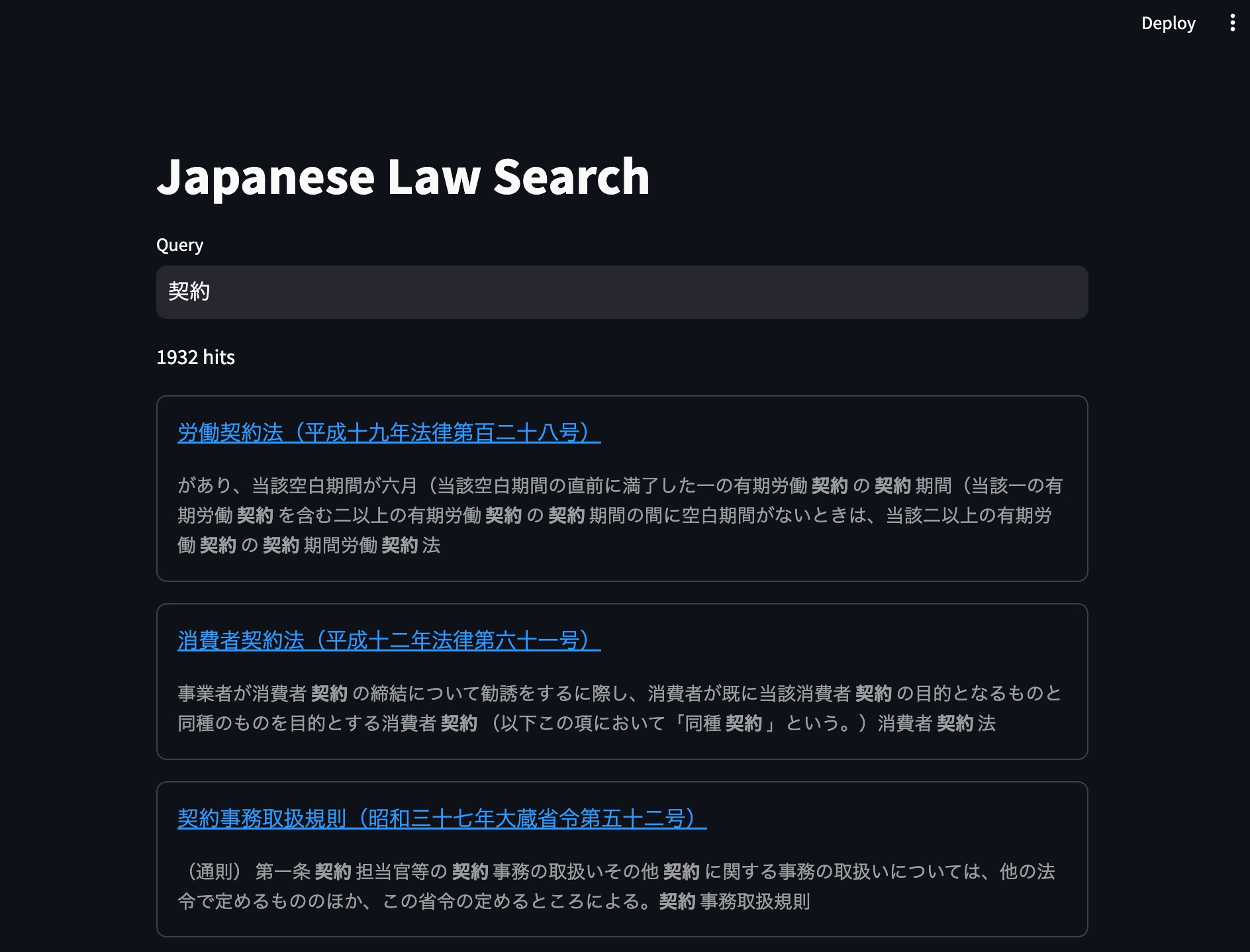
ドキュメント数が少なくクエリも単純なので、結果は瞬時に返ってきます。ハイライトがあると、どの条文にヒットしたのかわかりやすくていいですね。ただ、ヒットした条番号と、条文の全文が表示されると、より使い勝手がよくなりそうな気がします[17]。
おわりに
この記事では、日本の法令制度について概観したあと、デジタル庁が公開している法令データの形式を解説し、それをパースするPythonライブラリを紹介しました。
さらに、Elasticsearchを使って、実際に法令データのインデックスと検索を実装するサンプルを見てきました。今回はとりあえず動くサンプルを雑につくりましたが、マッピングやクエリ、言語解析(analyzer)などを改善することで、もっとよい法令検索がつくれるのではないかと思います。
みなさんが法律や法令について、少しでも身近に感じられるようになったなら幸いです。
2021年よりe-Gov法令検索は総務省からデジタル庁に移管されました。 https://www.e-gov.go.jp/news/2021-09-02t1914240900_715.html ↩︎
法律 - Wikipedia https://ja.wikipedia.org/wiki/法律 ↩︎
法律ができるまで(内閣法制局) https://www.clb.go.jp/recent-laws/process/ ↩︎
日本-法令の調べ方 - リサーチ・ナビ(国立国会図書館) https://rnavi.ndl.go.jp/jp/guides/japan-hourei-research.html ↩︎
いしかわ まりこ; 藤井 康子; 村井 のり子. リーガル・リサーチ . 日本評論社. https://www.nippyo.co.jp/shop/book/7055.html ↩︎ ↩︎
法令 - Wikipedia https://ja.wikipedia.org/wiki/法令 ↩︎
全部改正にあたって、必要に応じて法令の題名が変えることがあります。たとえば、スポーツ基本法(平成二十三年法律第七十八号)は、スポーツ振興法(昭和三十六年法律第百四十一号)が全部改正された法令です。 https://houseikyoku.sangiin.go.jp/column/column039.htm ↩︎
DB登録法令数(e-Gov法令検索) https://elaws.e-gov.go.jp/registdb/ ↩︎
ヘルプ - e-Gov法令検索 https://elaws.e-gov.go.jp/help/ ↩︎
法令IDについて(e-Gov法令検索) https://elaws.e-gov.go.jp/file/LawIdNamingConvention.pdf ↩︎
例外として、法令データのなかには、条(
Article)から始まらず、項(Paragraph)から始まる法令もあるため、注意が必要です。例:有明海及び八代海等を再生するための特別措置に関する法律第十一条第一項に規定する特定事業を定める省令(令和三年総務省令第四十四号) ↩︎法令とは?法律との違いや読み方のコツを解説! - 契約ウォッチ https://keiyaku-watch.jp/media/kisochishiki/hourei_yomikata/ ↩︎
Geminiなどで条文の文埋め込みを計算し、ElasticsearchのkNN searchで検索する、というのも試してみたかったのですが、時間が足りなかったので今後の宿題とします。 ↩︎
もしかしたら、条の単位をドキュメントとしてインデックスし、パッセージ検索のような形にするのがいいのかもしれません。スコアリングは難しくなりそうですが。 ↩︎